구글에 올라온 건 대부분 VMWare 통해서 가상장치에서 설정하는게 대부분이었다. 나는 공부하는게 아니라 로컬 서버를 구성해야 하기 때문에 대부분 자료들은 걸러졌다.
우선 시도하다가 의문점이 생겼다.
1. Hardware RAID
이건 메인보드에서 지원을 하는지가 중요하다. 우선 내가 지금 하고 있는 서버는 지원이 가능한데 RAID 레벨이랑 디스크 설정이 어떻게 하는지가 없다... 이부분은 서버 제조사에 문의를 해봐야한다. 우선 BIOS에서 RAID를 하였지만 리눅스 계열 OS 설치과정에서 RAID 한 것 처럼 보이지가 않고 각각 HDD가 따로 보인다. 이대로 OS를 설치하면 error가 발생하면서 설치가 되지 않았다.
2. Software RAID
(1) OS 설치할 때 RAID 하거나 (2) ubuntu OS 설치 이후에 명령어를 통해서 하는 방법이다.
3. 파일시스템 디스크를 포함한 RAID 구성 - 이 부분은 궁금증이다.
OS 설치할 때 RAID 구성은 아주 간단했다. 디스크 설정만 하면 됐다. 그런데 문제는 boot 디스크는 남겨야한다. 즉 디스크가 8개가 있으면 1개는 파일시스템을 받아야하기 때문에 남기고 나머지 7개만 RAID 구성을 한다는 얘기다. /boot, / , SWAP 은 1개의 디스크에만 설치하고 나머지 7개만 RAID 구성을 하였다. 이게 맞는지 잘 모르겠다. 지인은 이게 맞다고 하는데...
다른 글에서 RAID를 하는 과정을 포스팅할 예정이다. Hardware RAID는 해봤는데 해당 메인보드 버전에 따른 문제가 생겨서 복잡했고 이 회사 메인보드가 아니라면 해당사항 또한 없기 때문에 불필요할거라 생각된다.
그렇기 때문에 Software RAID 만 할 쓸 예정이다. 우선 OS 설치시 IP 설정 또한 같이 다루면 편할 듯 싶다.
복수 배열 독립 디스크(Redundant Array of Independent Disks 혹은 Redundant Array of Inexpensive Disks)는 여러 개의 하드디스크에 일부 중복된 데이터를 나눠서 저장하는 기술이다.
즉 여러 개의 디스크를 하나로 묶어 하나의 논리적 디스크로 작동하게 하는데, 하드웨어적인 방법과 소프트웨어적인 방법이 있다. 하드웨어적인 방법은 운영체제에 이 디스크가 하나의 디스크처럼 보이게 한다. 소프트웨어적인 방법은 주로 운영체제 안에서 구현되며, 사용자에게 디스크를 하나의 디스크처럼 보이게 한다.
초기에는 HDD 업그레이드 후 폐기하기엔 아깝고 그렇다고 쓰기에는 성능이 떨어져서 계륵과 같은 HDD를 재활용할 목적으로 사용했다. 그래서 초기에는 Inexpensive로 사용하였는데 현재는 Independent 의미로 사용한다.
RAID는 저장장치의 가용성과 성능 향상에 의미를 두고 있다. 단순히 데이터 백업의 용도로 사용되는 기술이 아니다. 디스크의 고장나도 고장난 디스크만 교체해주면 서버 정지 하지 않아도 복구가 가능하다. 이런 기능을 보고 백업에 의미만 생각하지 않았으면 좋겠다. 요즘 같은 경우는 미러링 서버나 다른 데이터 백업 솔루션을 마련해 둔다.
1. RAID 0 - Striping, 스트라이핑(부르는 사람 맘인듯하다...난 스트리핑이라고 부름...)
여러 개의 멤버 하드디스크를 병렬로 배치하여 거대한 하나의 디스크처럼 사용한다. 데이터 입출력이 각 멤버 디스크에 공평하게 분배되며, 디스크의 수가 N개라면 입출력 속도 및 저장 공간은 이론상 N배가 된다. 다만 멤버 디스크 중 하나만 손상 또는 분실되어도 전체 데이터가 파손되며, 오류검출 기능이 없어 멤버 디스크를 늘릴수록 안정성이 떨어지는 문제가 있다. 따라서 장착된 하드디스크의 개수가 RAID-5 구성 조건에 충족되지 않는 등의 불가피한 경우가 아니라면 절대로 RAID 0으로 구성하지 않는 걸 추천한다.
2. RAID 2 - Mirroring
RAID로 묶인 디스크끼리 같은 데이터를 기록한다. RAID로 묶인 디스크 중 하나만 살아남으면 데이터는 보존되며 복원도 1:1 복사로 매우 간단하기 때문에, 서버에서 끊김 없이 지속적으로 서비스를 제공하기 위해 사용한다.
디스크를 늘리더라도 저장 공간은 증가하지 않으며, 대신 가용성이 크게 증가하게 된다. 상용 환경에서는 디스크를 2개를 초과해서 쓰는 경우가 드물지만, 극한 환경에서는 3개 이상의 디스크를 사용하기도 한다. 읽기 성능이 향상되기도 하지만 쓰기를 시도할 때에는 약간의 성능 저하가 뒤따른다.
3. RAID 2~4
오류정정부호(ECC)를 기록하는 전용의 하드디스크를 이용해서 안정성을 확보한다. RAID 2는 비트 단위에 Hamming code를 적용하며, RAID 3, 4는 각각 바이트, 워드 단위로 패리티를 저장한다. 하나의 멤버 디스크가 고장나도 ECC를 이용하여 정상적으로 작동할 수 있지만, 추가적인 연산이 필요하여 입출력 속도가 매우 떨어진다. 예를 들어서 디스크 1에 3, 디스크 2에 6을 저장하면 디스크 3에는 1+2의 값인 9를 저장한다. 이렇게 저장하면 디스크 1이 사라지더라도 디스크 2의 6의 값을 읽고, 디스크 3의 9의 값에서부터 디스크 1의 값 3을 읽을 수 있기 때문에 저장소 하나가 파손되더라도 데이터를 읽을 수 있는 것이다. 용량을 약간 희생하지만 하드 하나만 뻑가도 망할 수 있는 일부 레이드 시스템에 비해 매우 높은 가용성과 저장용량 효율을 보인다.
모든 I/O에서 ECC 계산이 필요하므로 입출력 병목 현상이 발생하며, ECC 기록용으로 쓰이는 디스크의 수명이 다른 디스크들에 비해 짧아지는 문제가 있어 현재는 사용하지 않는다.
4. RAID 5
RAID 0처럼 데이터를 블록 단위로 디스크에 저장을 하는데 에러로 인한 손실 방지 패리티가 같이 저장된다, RAID 1처럼 디스크 1개가 고장이나도 고장난 디스크만 교체하면된다. 그런데 디스크가 두 개 이상 고장 나면 데이터가 모두 손실된다. 데이터베이스 서버 등 큰 용량과 무정지 복구 기능을 동시에 필요로 하는 환경에서 주로 쓰인다.
주의할점
(1) RAID 0보단 안전하다는 인식과 달리 오히려 많은 량(보통 8개 이상)의 디스크를 스토리지로 묶으면, 패리티 연산오류 발생 확률이 높아져서 인해 RAID 0으로 묶은 것보다 깨질 확률이 높아진다고 한다. 그러므로 대단위로 스토리지를 만드려면 RAID 6 또는 RAID 1+0을 권한다. 다만, 이는 레이드 대상 HDD가 7개 이하일 경우에는 해당되지 않는다.
(2) 고장난 장비를 교체하려다 고장 없는 하드디스크를 뽑는다면 RAID 전체가 망가진다. 동일 상황에서 RAID 6는 문제가 없다.
(3) 한 개의 디스크가 고장 났을 경우 고장난 하드를 교체하면 복구가 가능하지만 2개 이상의 디스크 고장이 나면 복구가 불가능하다.
즉 RAID 0에서 성능과 용량을 조금씩 줄이는 대신 안정성을 높인 레벨이라고 볼 수 있다.
RAID 6
RAID 5와 원리는 같다. 서로 다른 방식의 패리티 2개를 동시에 사용한다. 성능과 용량을 희생해서 가용성을 높인 셈. N개의 디스크를 사용하면 (N-2)배의 저장 공간을 사용할 수 있다. 비용이 RAID 5보다 더 비싸고, 디스크도 기본 4개 이상 확보해야 하므로 초기 구축 비용이 비싸다. 하드디스크를 대단위로 물려야 하고, 가용성의 필요성이 RAID 5보다 높아야 하는 상황에서 쓰인다.
6. Nested RAID
(1) RAID 0+1
RAID 0로 구성된 하드디스크들을 RAID 1로 미러링 한다. 하드디스크 2개를 RAID 0로 구성 한 후 다른 하드디스크 2개에 RAID 1 미러링을 합니다. 이럴 경우 같은 데이터가 저장된 디스크 0 , 2 또는 디스크 1 , 3 가 같이 고장 또는 다운이 된다면 복구 할 수 없다.
(2) RAID 1+0
RAID 1로 미러링 된 디스크를 RAID 0으로 구성한다. RAID 0+1에 비해 디스크 장애 발생 시 복구가 수월하다.
더 많은 Nested RAID 가 있지만 그 부분은 내가 하지 않을 것 같아 직접 찾아보기 바란다.
mysql> use mysql;
mysql> select user, host from user
user 추가
mysql> create user '사용자 이름 입력하세요'@'localhost(또는 %)' identified by '비밀번호 입력';
'localhost' or '%' or 'IP' : localhost는 해당 pc만 접속 , %는 외부의 모든 접속 가능, IP는 해당 IP만 접속 가능하다.
user 삭제
mysql> drop user '사용자명 입력'@'localhost';
해당 user의 접속 권한 또한 똑같이 입력해야 한다.
user DB 권한 부여 (Grant)
mysql> grant all privileges on *.* to '사용자'@'localhost';
mysql> grant all privileges on DB이름.* to '사용자'@'localhost';
mysql> grant all privileges on DB이름.테이블명 to '사용자'@'localhost';
mysql> grant select on DB이름.테이블명 to '사용자'@'localhost';
mysql> grant update(컬럼1, 컬럼2) on DB이름.테이블명 to '사용자'@'localhost';
1번 라인은 모든 DB, DCL을 제외한 권한을, 2번 라인은 특정 DB 권한 및 DCL을 제외한 권한을, 3번 라인은 특정 DB의 테이블에 대한 권한 4번 라인은 DB의 테이블에 대한 select 권한 5번 라인은 DB의 테이블에 대한 특정 컬럼 수정 권한이다.
이렇게 특정 DB의 권한을 줄 수도 있고 select, delect 등의 특정 권한만 줄 수도 있다.
all privieges는 모든 권한을 , *.*는 모든 DB의 모든 테이블을 뜻한다.
정리해보면 grant (권한) on (범위) to (user) 이렇게 정리할 수 있겠다.
1번 라인에 with grant option 을 맨 끝에 추가하면 권한 부여(ROOT 권한)을 부여한다.
user 권한 삭제 (Revoke)
이 부분은 Grant와 구조가 같다. 응용해서 특정 조건을 삭제할 수 잇다.
mysql> revoke all on DB명* from 'user'@'localhost';
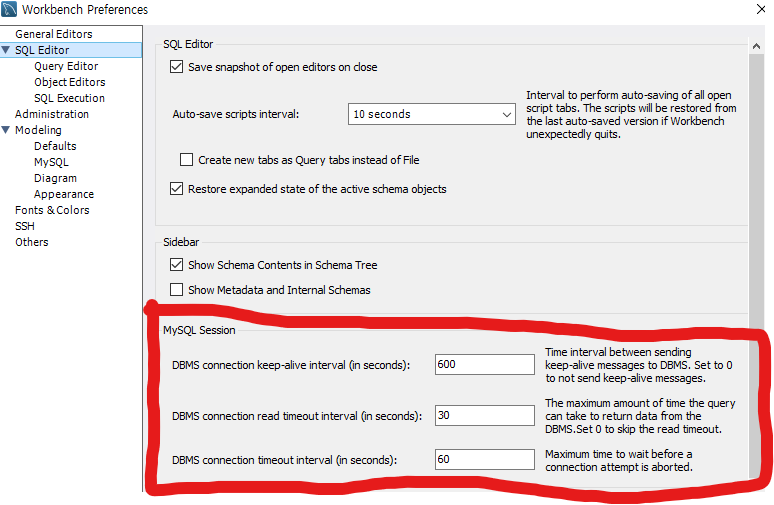
우선 편리를 위해 루트계정으로 했다. 설정 자체는 루트계정이 아닐경우 수정이 안되는 경우가 많고 sudo를 계속 치면서 pw를 치는게 번거롭다.
1. 방화벽 포트포워딩.
- 서버와 내가 사용하는 PC는 다른 IP이기 때문에 너무 당연한 거였다.
이 부분은 결정적인 원인은 아니다.
2. 우분투 IP 및 포트 개방.
- OS에서 포트가 개방 되어있는지 그리고 IP가 로컬로 되어있는지 확인을 했다.
netstat 명령어를 사용하면 된다.
# netstat -tnlp
기본적으로 MySQL은 3306 포트를 사용한다.
우선 Local Address를 살펴보면 3306포트가 127.0.0.1로 되어있는것을 확인할 수 있다. 그렇단 뜻은 로컬에서만 mysql을 접속 할 수 있다. 이건 mysql 설정을 바꿔주면 된다. 우선 맨끝에 프로그램 이름을 확인하자. mysqld 라고 되어있다. 이걸 기억한 후 mysql 폴더로 가야한다.
cd /etc/mysql
ls -a
mysql 폴더는 etc 밑에 있다. cd 명령어를 통해서 이동 후 ls 명령어를 통해서 폴더 안에 어떤게 있는지 확인한다.
여기서부터 문제가 많았다.
이 설정은 os 버전과 mysql 버전에 따라 설정 파일이 다를 수 있다. 나도 이 부분에서 굉장히 헤맸다. 어떤 사람은 my.conf , mysql.conf, mysqld.conf ... 어떤 사람은 이 폴더에서 찾는 사람도 있다. 많은 시도 끝에 해결했다. 우선 아까 프로그램이름이 mysqld 였는데 이 폴더 안에는 같은 이름의 cnf가 없었다.
그래서 mysql.conf.d 폴더로 이동했다. 그 안에 mysqld.cnf 파일이 있었다.
cd mysql.conf.d
ls -a
vi mysqld.cnf
vi로 mysqld.cnf 파일을 편집하자.
bind-address가 있다. 그걸 0.0.0.0으로 바꿔주자. 그리고 :wq를 입력하고 나오면 된다.
수정했다면 mysql를 재실행한다.
service mysql restart
재실행했으면 아까 netstat 명령어로 IP가 제대로 설정됐는지 확인해보자
이렇게까지 했으면 이제 Mysql에서 user를 살펴봐야한다.
3. User 설정
mysql에 root 계정으로 접속한다.
mysql -u root -p
접속 한 후 데이터베이스를 선택한 후 user 테이블을 확인해보자.
mysql> use mysql;
mysql> select user,host from user;
user 테이블을 보면 host 컬럼에 localhost만 되어있다. 이 뜻은 외부 접속이 안된다.
그러면 user를 하나 생성해주자.
mysql> create user 'user'@'%' identified by '!QAZ2wsx';
'user'@'%'는 user는 user name이고 , % 는 외부의 모든 접근 허용이다.